Politique
La fabrique des big data
21.10.2022

Cet article a paru dans le n°120 de Politique (septembre 2022).
Big data, « données massives » sont des termes qui vous disent certainement quelque chose. Le phénomène concerne quasiment tous les secteurs d’activité, privés et publics. Il est cependant toujours difficile d’en donner une définition précise. Dans le domaine professionnel, les acteurs – opérateurs, dirigeants, consultants, experts – parlent des « 3V » pour renvoyer aux trois caractéristiques principales du big data : la quantité massive de données disponibles qui se calculent en zettabytes[1. 1 octet ou byte correspond à 8 bits ; 1 gigaoctet ou gigabyte vaut 1 milliard d’octets et 1 zettaoctet correspond à 1021 bytes (1000 milliards de milliards de bytes). ] (volume), provenant de sources multiples selon différents formats (variété) et circulant en temps réel (vélocité). Plus récemment, 2V ont été ajoutés pour souligner l’objectif de monétisation des données (valeur) et la fiabilité des données en fonction de leur provenance, de leur type et de leur traitement (véracité).
Si vous interrogez des professionnels du secteur industriel pour savoir ce qu’est une donnée, certains vous diront qu’il s’agit d’un fait, d’une information. Et pourtant, la donnée n’est pas « donnée ». Elle est toujours le résultat d’un travail, de négociations, de conventions. Comme l’or ou le pétrole, la donnée est une matière première qui, une fois extraite et exploitée, constitue une source d’énergie créatrice de valeur. Elle est le carburant qui permet aux organisations d’avancer dans le monde de plus en plus digital. Cependant, à la différence du pétrole, la donnée « brute » ne dépend pas de facteurs géologiques, mais apparaît au sein de dispositifs mis en place par des hommes et des femmes. L’aura de neutralité et d’objectivité dont bénéficient les données est donc à nuancer. Je reviendrai un peu plus loin sur le processus de fabrication des données.
Les données ne sont pas neuves
Il y a une profusion de discours sur les big data ou données massives « avec la mise en place d’un monde de données »[2.D. Cardon, « Regarder les données », Multitudes, 2 (49), 2012, p.138.]. Pourtant, les données existent depuis longtemps, sous une forme analogique d’abord, puis numérique. Selon Angèle Christin, professeure au département de Communication de l’Université de Standford, « le mot “datum” a commencé à être utilisé au XVIIe siècle pour décrire des preuves scientifiques », et dans les années 1940, le mot anglophone data, au pluriel, était utilisé pour parler des opérations informatiques[3.A. Christin, “What Data Can Do: A Typology of Mechanisms”, International Journal of Communication, 14, 2020, p. 1116.]. Ce qui est novateur avec les big data, c’est la disponibilité des données (via Internet, les sites web et les objets connectés tels que les téléphones, les montres, les téléviseurs, les voitures, les drones, les robots ménagers, etc.) et la capacité technologique (notamment la puissance des machines et le développement de l’informatique en nuage ou cloud computing) pour les stocker et les traiter. Il existe également un environnement social et politique favorable au développement et à l’usage de ces données.
Le besoin de quantifier
Dans une société capitaliste, les organisations modernes sont caractérisées par la rationalisation, comme l’observait Max Weber lors des transformations de la fin du XIXe siècle. Il s’agit de rendre « rationnel » les processus de travail en orientant les actions vers les buts à atteindre, telle que la croissance de l’entreprise, l’accumulation et la circulation du capital. La prévision et l’anticipation, selon une recherche constante d’efficacité, passent peu à peu par les méthodes quantitatives en tant qu’outil d’aide à la décision. Qu’il s’agisse de gouvernements ou d’entreprises, les instruments de mesure et de statistique sont mobilisés pour décrire le réel, expliquer une situation en quantifiant les activités et les comportements humains. Prétendument objectifs, ils fournissent des informations sur le fonctionnement de l’entreprise, la performance des travailleurs, le comportement des consommateurs et réduisent la part de subjectivité dans les décisions.
Dans cette logique, les données massives sont mobilisées en vue d’obtenir une « vision 360 » du client ou de l’activité, aussi appelée « hélicoptère », c’est-à-dire la possibilité de se rapprocher du terrain pour gérer le court terme et de s’en éloigner pour avoir une perspective à long terme. Celle-ci est matérialisée par des tableaux de bord et des rapports régulièrement envoyés aux destinateurs cibles de façon automatisée. Grâce aux techniques quantitatives, les données décrivent, expliquent, voire prédisent certains évènements. Elles permettent ainsi de réduire l’incertitude et de traiter des problèmes auxquels font face toutes les organisations. La pandémie en est un exemple patent : les femmes et hommes politiques s’appuient sur les données – les chiffres de contamination au covid-19 et d’admission à l’hôpital – pour décider de confiner ou de déconfiner une population. Il s’agit de « gouverner par les nombres » comme l’exprime le statisticien français Alain Desrosières[4. A. Desrosières, Gouverner par les nombres : L’argument statistique II, Presses des Mines, 2008.]. Cette démarche correspond à un besoin de quantifier.
Capter l’attention
L’enjeu commercial majeur de l’exploitation des données est la captation de l’attention. Herbert Simon notait que l’abondance d’informations crée une pauvreté d’attention[5.H. A. Simon, “Designing organizations for an information-rich world”, Computers, communications, and the public interest, vol. 72, 1971.]. Et qui dit rareté, dit ressource de valeur. Le modèle économique des plateformes numériques, telles que Google et Facebook, repose sur le temps passé chez elles et le nombre de traces que vous y laissez. Lorsque Facebook vous envoie une notification sans réelle importance, elle s’assure que vous reveniez chaque jour sur la plateforme, lui permettant ainsi de mieux vous connaître et de vendre aux annonceurs du « temps de cerveau disponible[6. Formule choc de Patrick Le Lay, patron de TF1, en 2004, à propos du métier de la chaine audiovisuelle française.] ». À la différence des plateformes, les médias produisent du contenu journalistique et investissent dans les données massives en vue d’offrir « la bonne information, au bon endroit et au bon moment ». La personnalisation de l’information de masse permet par ailleurs d’obtenir un avantage concurrentiel : le média qui vous envoie chaque matin une newsletter personnalisée, en fonction de vos intérêts, améliore son service et se démarque ainsi de la concurrence.
L’avantage sur la concurrence appartiendra au média qui aura le mieux réussi à vous connaître en étudiant votre profil (âge, genre, profession, adresse du domicile) et votre comportement (contenus consultés, temps de lecture, lieux d’intérêt, commentaires, abonnement, etc.). Du point de vue de la connaissance de l’activité, l’exploitation de données permet également d’améliorer la performance de l’entreprise en réduisant les coûts de production par la digitalisation et l’automatisation renforcée des processus de travail.
L’enjeu politique porte lui aussi sur la publicité, dans le sens de rendre public. Les données sur le fonctionnement de l’État, l’activité des fonctionnaires et le comportement des citoyens constituent « l’expression d’une transparence revendiquée dans un contexte de corruption grandissant, la réponse à une demande de retour sur investissement face à des dépenses publiques critiquées, la contribution à des objectifs d’efficience accrue pour des appareils d’État souvent paralysés par l’inertie de leur organisation[7.G. Chartron, E. Broudoux, « Enjeux géopolitiques des données, asymétries déterminantes », in Big data – Open data : Quelles valeurs ? Quels enjeux ?, De Boeck Supérieur, 2015, p. 65-83.] ». Il suffit de repenser à l’affaire Snowden – du nom de cet informaticien qui a dévoilé en 2013 l’existence d’un programme de surveillance de masse par les États-Unis de personnalités politiques et de citoyens dans le monde – pour prendre conscience de l’étendue des possibilités de surveillance des individus par la collecte des données de messagerie personnelle ou d’entreprises. Le risque est également de se rendre dépendant aux géants numériques, les Gafam (Google, Apple, Facebook, Amazon, Microsoft).
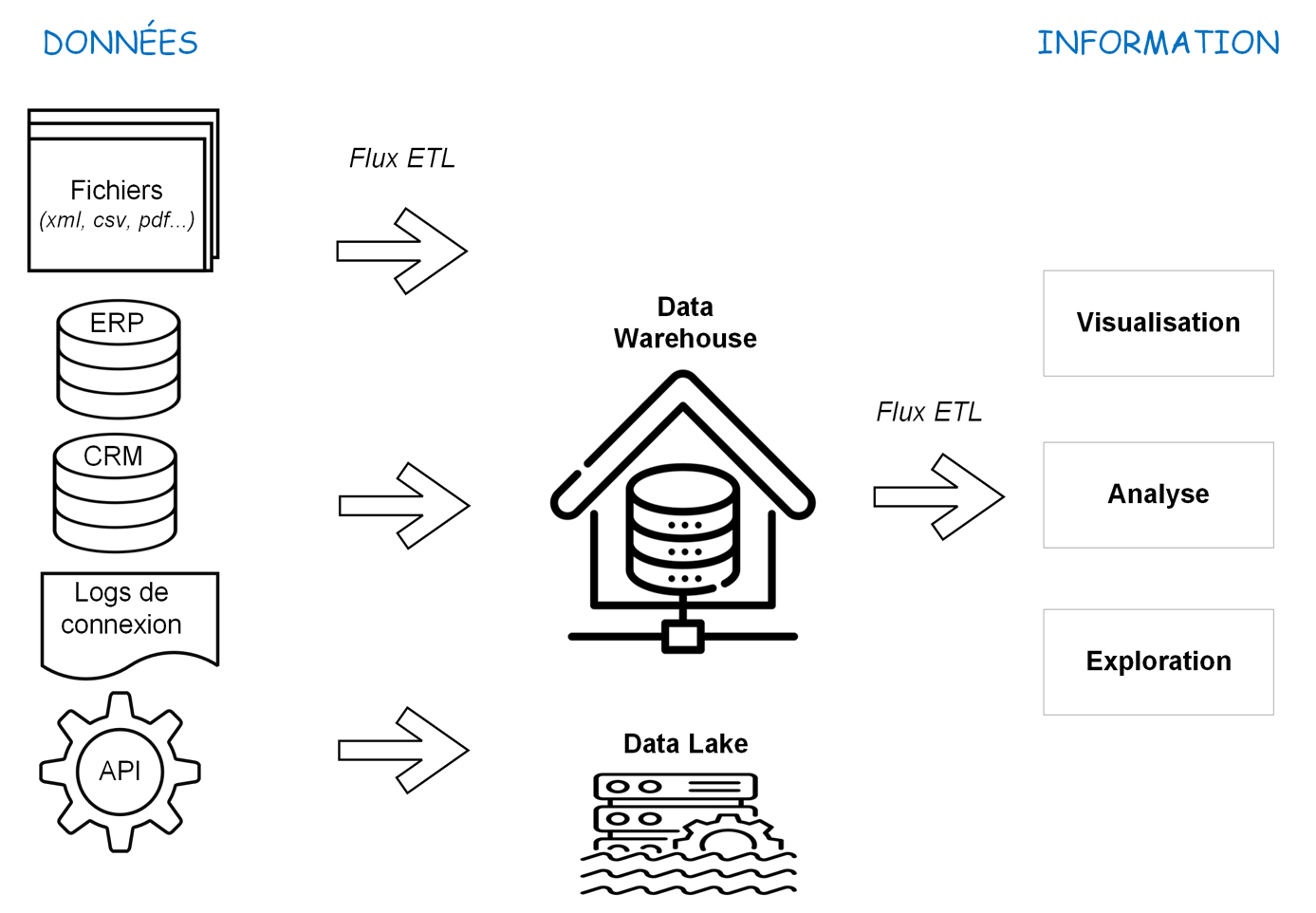
La production : des données à la connaissance
Comprendre comment les Gafam peuvent collecter des données sur vous, c’est s’intéresser au processus de fabrication des données. Celui-ci se réalise en trois grandes phases : la collecte, l’extraction-transformation-stockage et l’exploitation. Ces étapes sont successives, mais pas linéaires, plusieurs allers-retours sont effectués entre l’une et l’autre étape durant le processus de production.
Première étape, la collecte consiste à récupérer et stocker toutes sortes de données par le biais de systèmes informatiques tels que les ERP (Enterprise Resource Planning, ou système de gestion comprenant plusieurs applicatifs), les réseaux sociaux, l’open data, etc. Les données se présentent sous différents formats – bases de données, images, vidéos, fichiers CSV, XML, PDF – et peuvent découler d’un comportement en ligne mais aussi d’un comportement physique comme l’abonnement à un service via un formulaire papier. Les données qui sont collectées par les différents systèmes ne communiquent généralement pas entre elles. Il est donc difficile de les comparer. De plus, les données y sont généralement stockées dans leur version la plus récente.
Cette première étape est en réalité précédée d’une autre, plus discrète, celle du choix et de la configuration de ces systèmes. Ces opérations influencent les données captées. Par exemple, sur les réseaux sociaux, vous avez la possibilité de « liker » ou de ne pas cliquer. Si vous ne cliquez pas, la plateforme peut alors interpréter votre comportement de deux manières : vous n’aimez pas le contenu proposé ou vous n’avez pas d’avis à son propos. Votre comportement, tout comme celui de millions d’autres utilisateurs, sera analysé, interprété au regard de ces deux possibilités – a cliqué sur « j’aime » ou n’a pas cliqué –, en fonction de votre vitesse de scroll (faire défiler) et donc du temps de lecture, du trajet de votre souris éventuelle, des autres contenus consultés, de votre profil, des autres pages web consultées avant et après ce site, etc.
Un actif stratégique
L’étape suivante consiste à extraire les données des systèmes sources et à les mettre dans un entrepôt de données (Data Warehouse). Celui-ci se présente sous la forme d’une grande base de données[8.Une base de données (relationnelle) comprend une ou plusieurs tables – une table ressemble à un tableau Excel avec des lignes et des colonnes – qui forment en général un schéma en étoile avec une table (de fait) au centre, reliant les tables (de dimensions).] capable de conserver un historique des données et de faciliter les croisements et les comparaisons entre elles (après les avoir transformées pour qu’elles soient comparables). Il répond au besoin des organisations de centraliser les données. Les données y seront « structurées », c’est-à-dire qu’elles ont été formatées selon une structure précise. Pour obtenir ce résultat, il faut utiliser un outil d’ETL (Extract Transform and Load) qui va se connecter aux différents systèmes sources pour aller chercher les données, les transformer pour assurer une cohérence entre toutes les données et les charger dans l’entrepôt de données. Cette tâche ETL est divisée en une multitude de petites tâches simples à exécuter, telles que le calcul, les tests, les modifications, le contrôle, le nettoyage, la conversion. Imaginons que le logiciel comptabilité de l’entreprise encode l’adresse du client M. Martin selon le champ « code postal + commune », tandis que le nouvel ERP qui gère les abonnements de M. Martin encode « code postal » et « commune » dans deux champs distincts. L’outil ETL va transformer l’une de ces données pour qu’une fois dans l’entrepôt, M. Martin n’ait qu’un seul format d’adresse. Le nettoyage aura également enlevé les « 0 » ou espaces vides en trop. Ce qui aura permis de standardiser (normaliser) toutes les données. Petit détail : ETL, de son petit nom, vous paraît peut-être anodin, un outil parmi tant d’autres, né avec la création d’entrepôts de données… il est pourtant aujourd’hui un acteur central dans la fabrication des données, disposant d’une spécialisation de métier et d’outils rien que pour lui.
Nous venons de parler de l’entrepôt de données, et donc de données structurées. Mais l’organisation peut aussi choisir de mettre toutes les données dans un lac de données (data lake). Celui-ci ressemble à un grenier dans lequel on décide de stocker des objets non triés – des données non structurées – dont on se préoccupera plus tard mais qu’on est sûr de posséder. Cela rejoint le principe d’accumulation du capital, les données étant un actif stratégique de l’organisation puisqu’elles constituent une ressource génératrice d’avantages économiques futurs. Et le processus d’accumulation est ici simple puisqu’avant de jeter une donnée dans le lac, il suffit simplement de lui apposer une étiquette ou drapeau afin de pouvoir la retrouver ensuite. Un peu comme lorsque vous jetez vos lunettes de natation dans la piscine, si vous n’indiquez pas tout de suite un point de repère, ce sera assez compliqué de les retrouver par la suite. Cette pratique est sécurisante mais ne participe pas à une gestion durable des données. En effet, le coût de stockage des données est aujourd’hui très faible – pensez à vos photos et fichiers que vous stockez en masse sur le cloud via Dropbox, OneDrive, etc., grâce à un compte gratuit. Ces conditions avantageuses n’incitent pas vraiment à s’interroger sur les coûts environnementaux que représente notamment la consommation énergétique des data centers.
La dernière étape consiste à exploiter les données pour comprendre une situation passée, prédire une situation future ou suivre l’activité en cours. Pour faciliter l’expérience des décideurs avec les données massives, les travailleurs de la donnée configurent les outils de reporting, les outils de visualisation, et s’assurent de la circulation des données entre les différentes applications. Ils peuvent également, à un niveau de compétences avancé, utiliser les techniques de fouille de données (data mining) pour explorer les données, en extraire de l’information et modéliser des situations ou des comportements en vue de les anticiper. Le travailleur de la donnée devient alors maître des données et apprend à la machine comment construire et développer le modèle (machine learning) pour qu’elle puisse ensuite répéter le processus, s’améliorer et exécuter des tâches de plus en plus importantes. L’algorithme, au départ proposé par le travailleur, est entrainé et devient auto-apprenant comme un athlète aux Jeux Olympiques. C’est l’une des disciplines de l’intelligence artificielle.
Voici brossé synthétiquement le processus de fabrication qui fait passer la donnée à l’état de connaissance, en passant par le statut d’information. Pour rappel, la donnée est l’élément telle que la mesure indiquée sur le thermomètre (3 degrés), l’information est le fait qu’il fait froid et la connaissance résulte de l’interprétation de l’élément initial, croisé avec d’autres informations et notre expérience personnelle (risque de refroidissement). De ce processus découle une prescription : s’habiller chaudement.
Les métiers de la donnée
Parfois confondus dans les organisations avec les informaticiens, les travailleurs de la donnée sont spécialisés dans une tâche du processus, dans un outil informatique dédié ou occupent des fonctions managériales. Les appellations sont nombreuses et évolutives mais parmi les plus courantes, on retrouve le data scientist, élu « job le plus sexy du XXIe siècle » par la Harvard Business Review. Ce scientifique des données dispose de compétences en sciences informatiques, en modélisation, en ingénierie et en apprentissage automatique (machine learning). Il utilise les outils complexes tels que Python ou R pour transformer les données et tester des hypothèses en vue d’expliquer un phénomène, selon une démarche scientifique issue de la statistique. On retrouve également le data analyst qui est davantage spécialisé dans la visualisation et l’analyse de données par le biais des outils de l’informatique décisionnelle (Business Intelligence) : Power Bi, Tableau, Qlik Sense, Excel, etc. Il détricote les données pour les rendre intelligibles par les décideurs et les opérationnels amenés à prendre des décisions sur base de ces données. L’architecte, quant à lui, construit et gère l’infrastructure informatique accueillant les données. Le délégué à la protection des données (Data Protection Officer ou DPO) est, depuis le 25 mai 2018, le pilote de la gouvernance des données personnelles, celui qui s’assure de la conformité au règlement général sur la protection des données (RGPD).
(Image de la vignette et dans l’article sous CC-BY 2.0 ; word cloud créé par EpicTop10.com en juillet 2019.)
